Blog
Updates & case studies
Deep dives into our projects, benchmarks, and experiments in frontier agent evaluation.
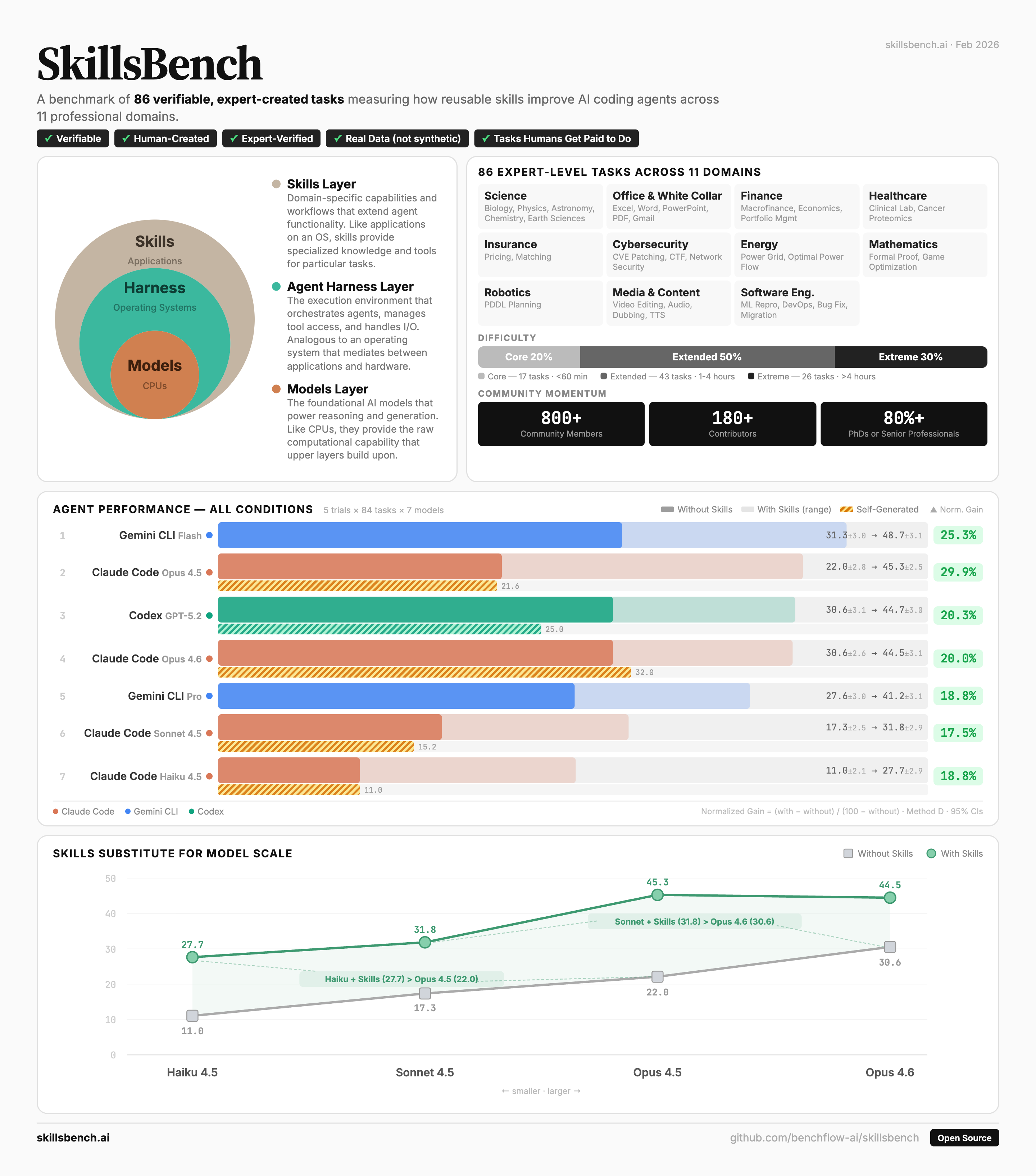
SkillsBench
The first evaluation framework measuring how skills (custom instructions) work for AI agents. 84 expert-curated tasks across diverse, high-GDP-value domains. The first dataset measuring how powerful models are at using skills.
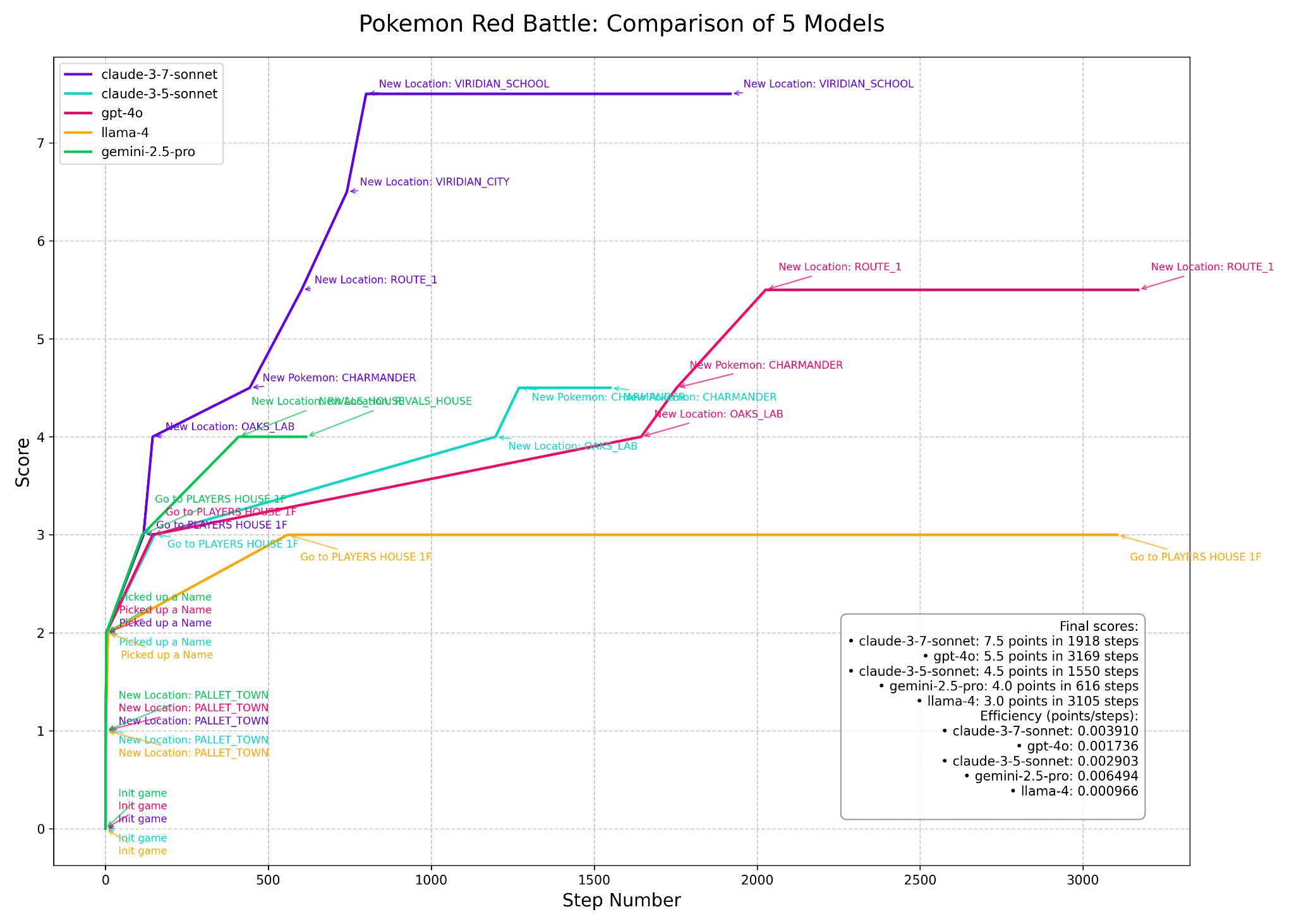
PokemonGym
First open-source harness for any LLM and agent to play Pokemon Red and Blue. Tests vision, reasoning, planning, memory, and sequential decision-making. Featured in the Gemini model launch.
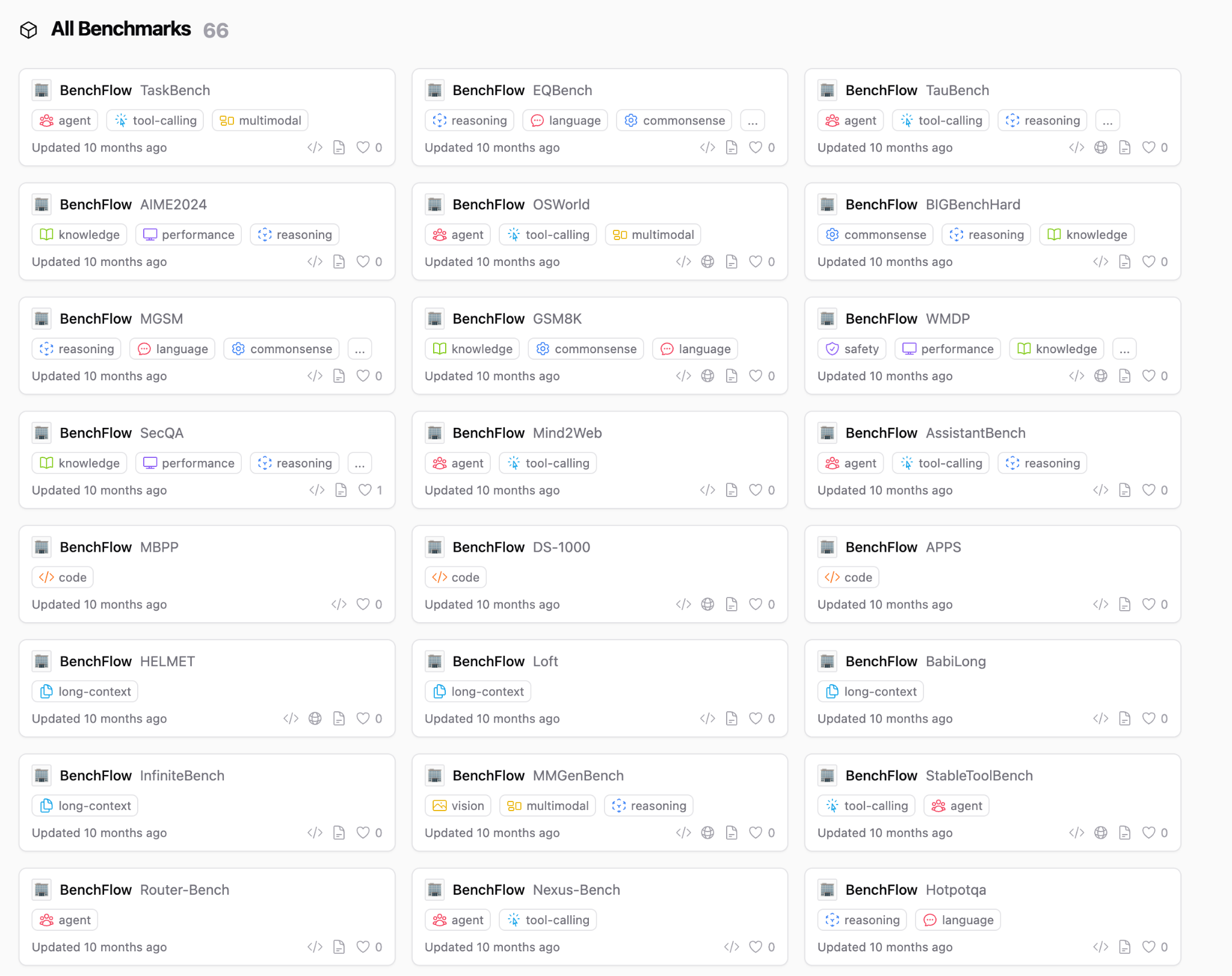
BenchFlow Hub & Runtime
The first protocol for agent and benchmark unification. HuggingFace for benchmarks and RL environments. One-line setup for 60+ benchmarks spanning NLP, web agents, code, medical AI, and more.
More
Experiments
Vibe Code Arena
ActiveArena-style evaluation for judging which vibe coding platform produces the most favorable output.
April 2025
Harbor DataGen
ActiveSynthetic data generation for terminal-based agent training. Powered by TerminalGym.
2025
MiniClaw
BetaClaude Code on your iMessage. AI coding assistant in your pocket.
2025