SkillsBench
Agent Skills Evaluation
January 2026
84
Tasks
7
Models
6+
Domains
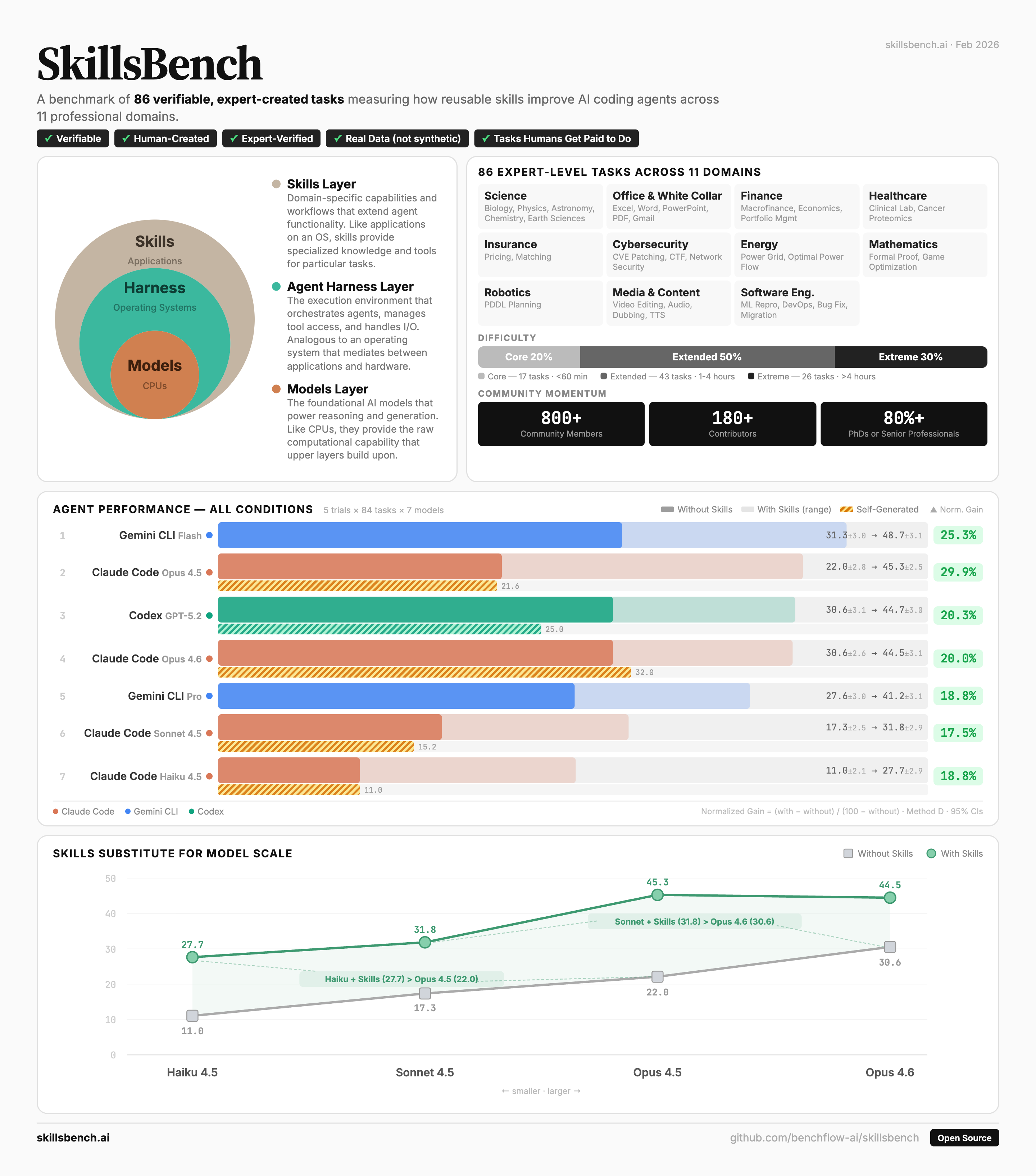
SkillsBench is the first evaluation framework designed to measure how skills — custom instructions and tool configurations — affect the performance of AI coding agents. It provides a standardized way to test whether giving agents domain-specific guidance actually improves their ability to complete real-world tasks.
The benchmark comprises 84 expert-curated tasks spanning 6+ professional domains including science, finance, healthcare, cybersecurity, energy, and software engineering. Each task uses real data and is verified by domain experts.
We evaluated 7 frontier models (Opus 4.5/4.6, Sonnet 4.5, Haiku 4.5, GPT-5.2, Gemini 3 Flash/Pro) across 3 conditions: no skills, with curated skills, and with self-generated skills. Results are scored using the Terminal-Bench Method D (task-mean with fixed denominator) across 5 trials per task — 420 trials per configuration.
Gallery
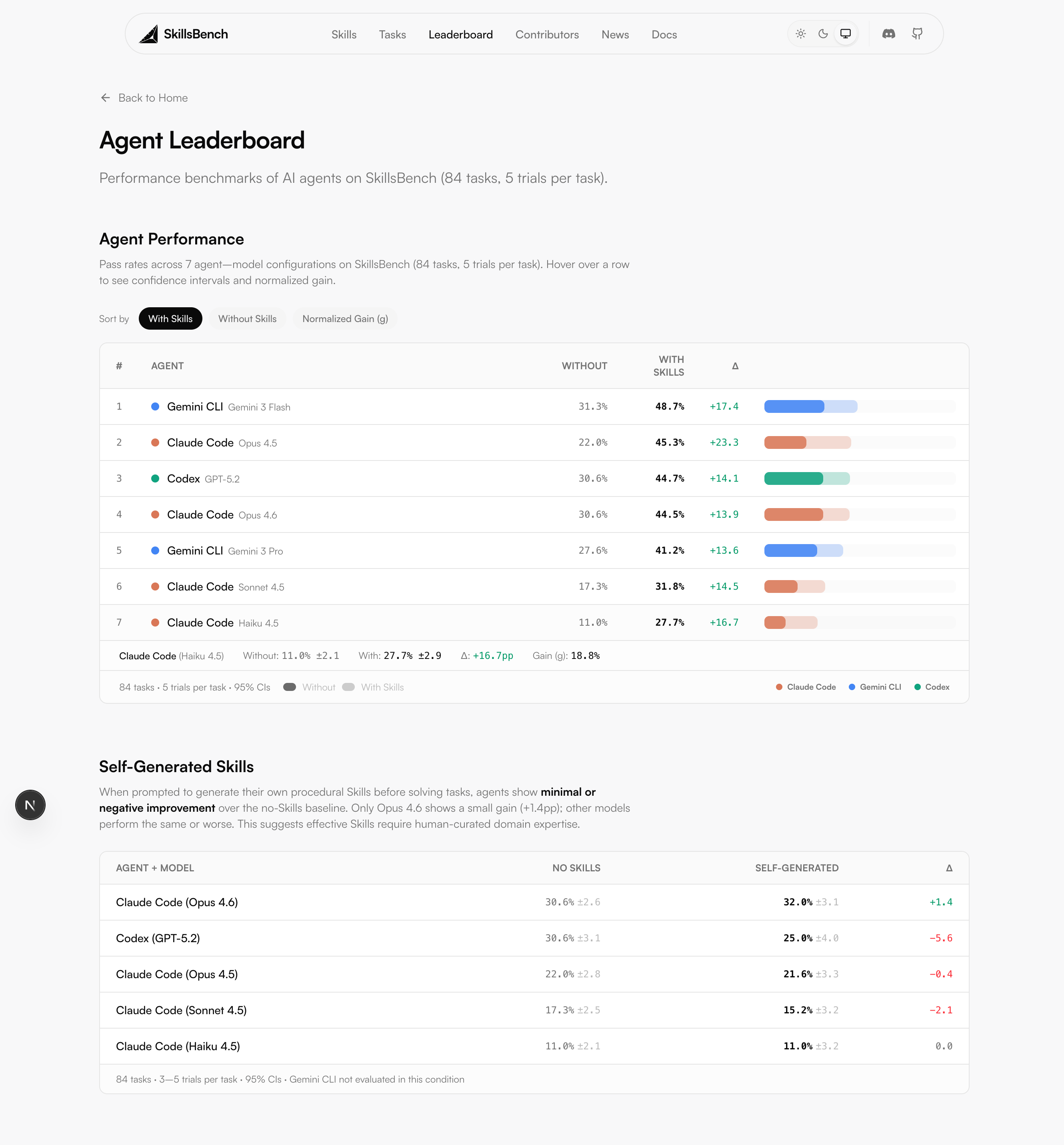
Interactive leaderboard with filtering and sorting
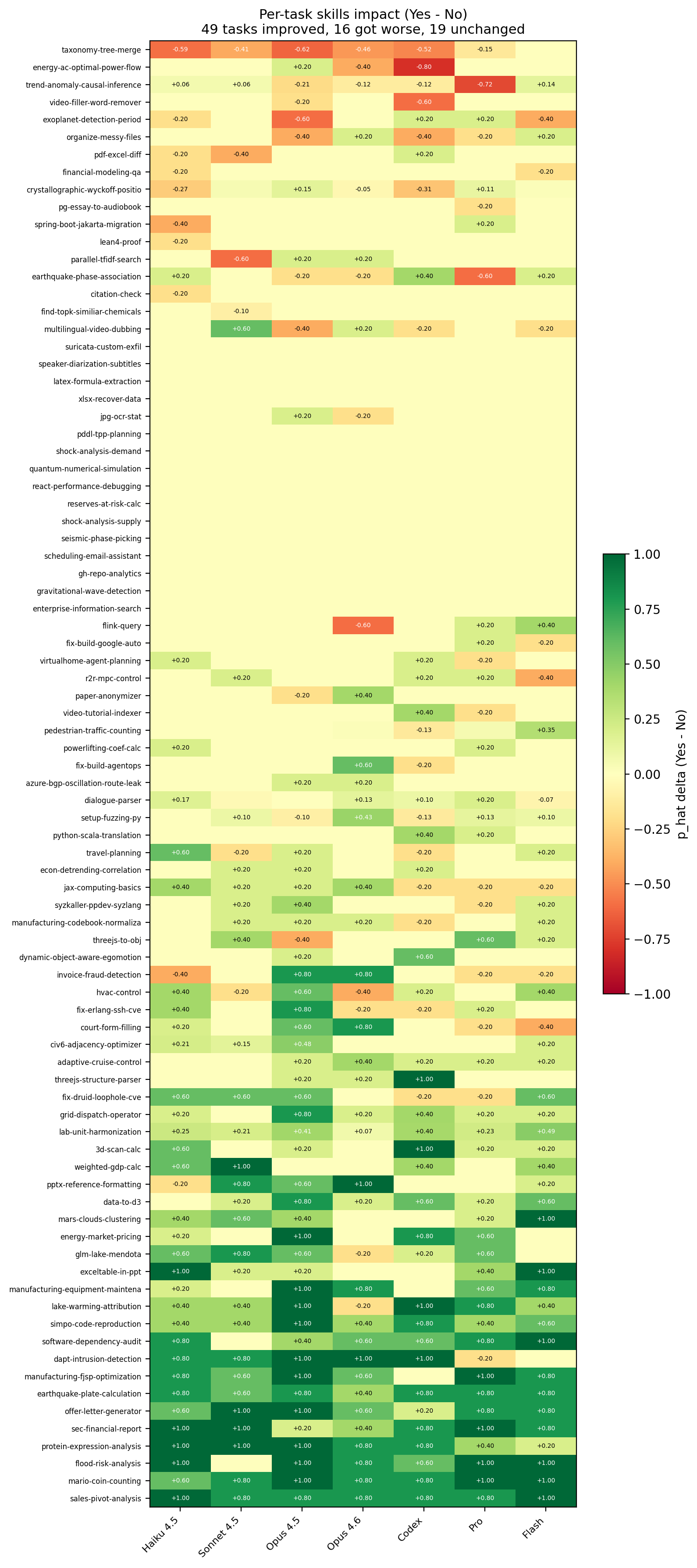
Per-task skills performance heatmap across models
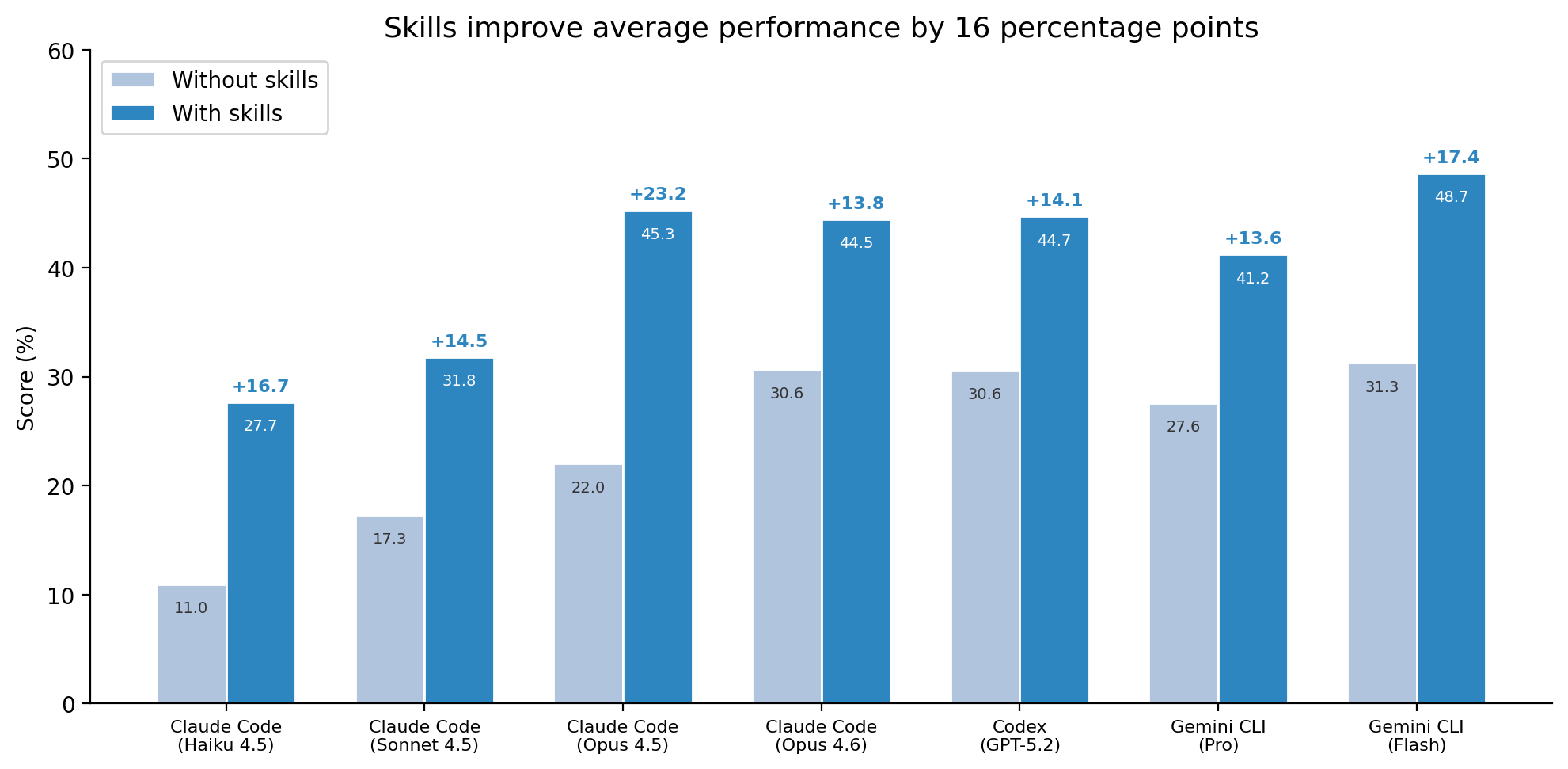
Skills performance across configurations
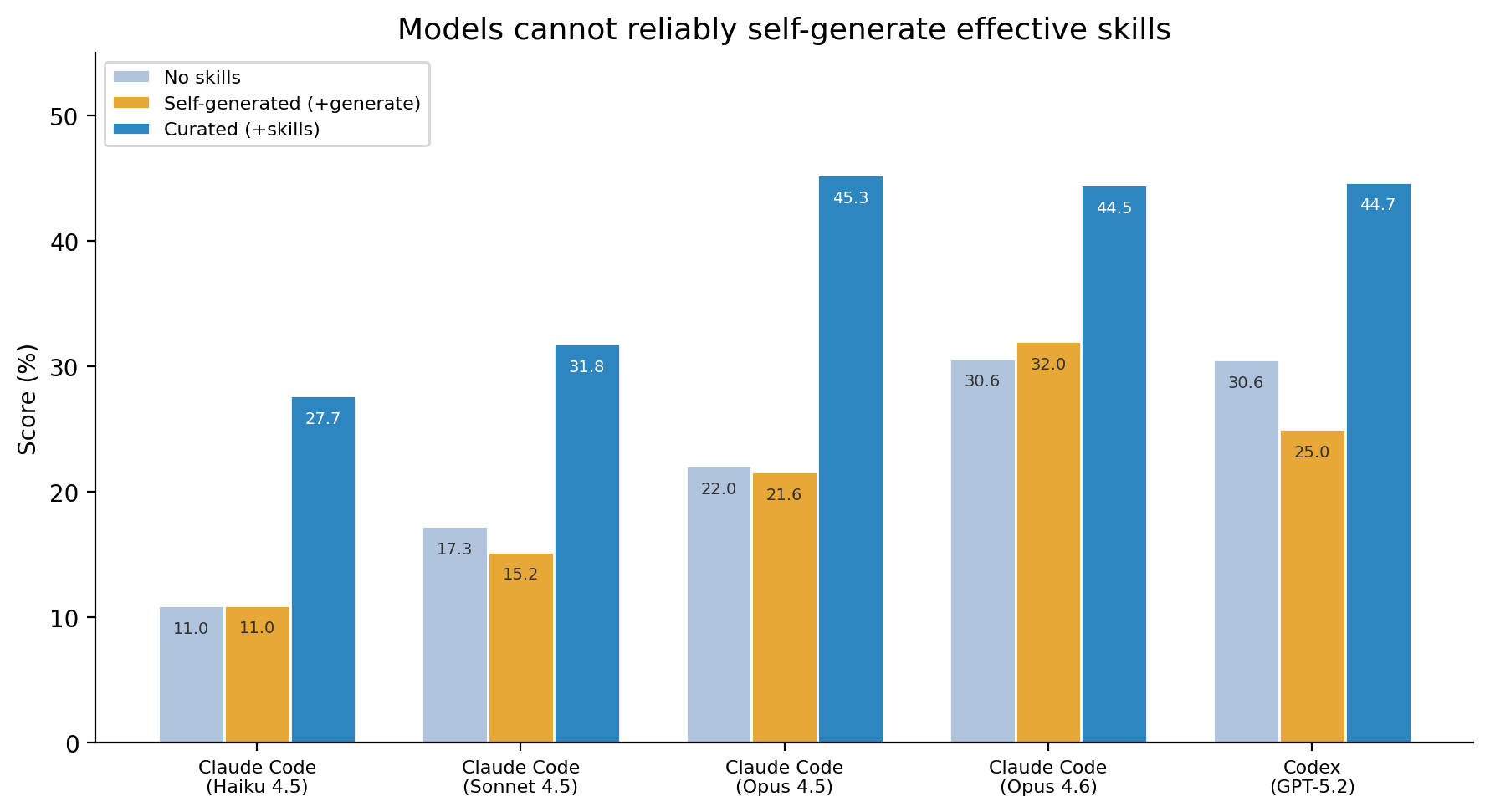
Self-generated vs curated skills comparison
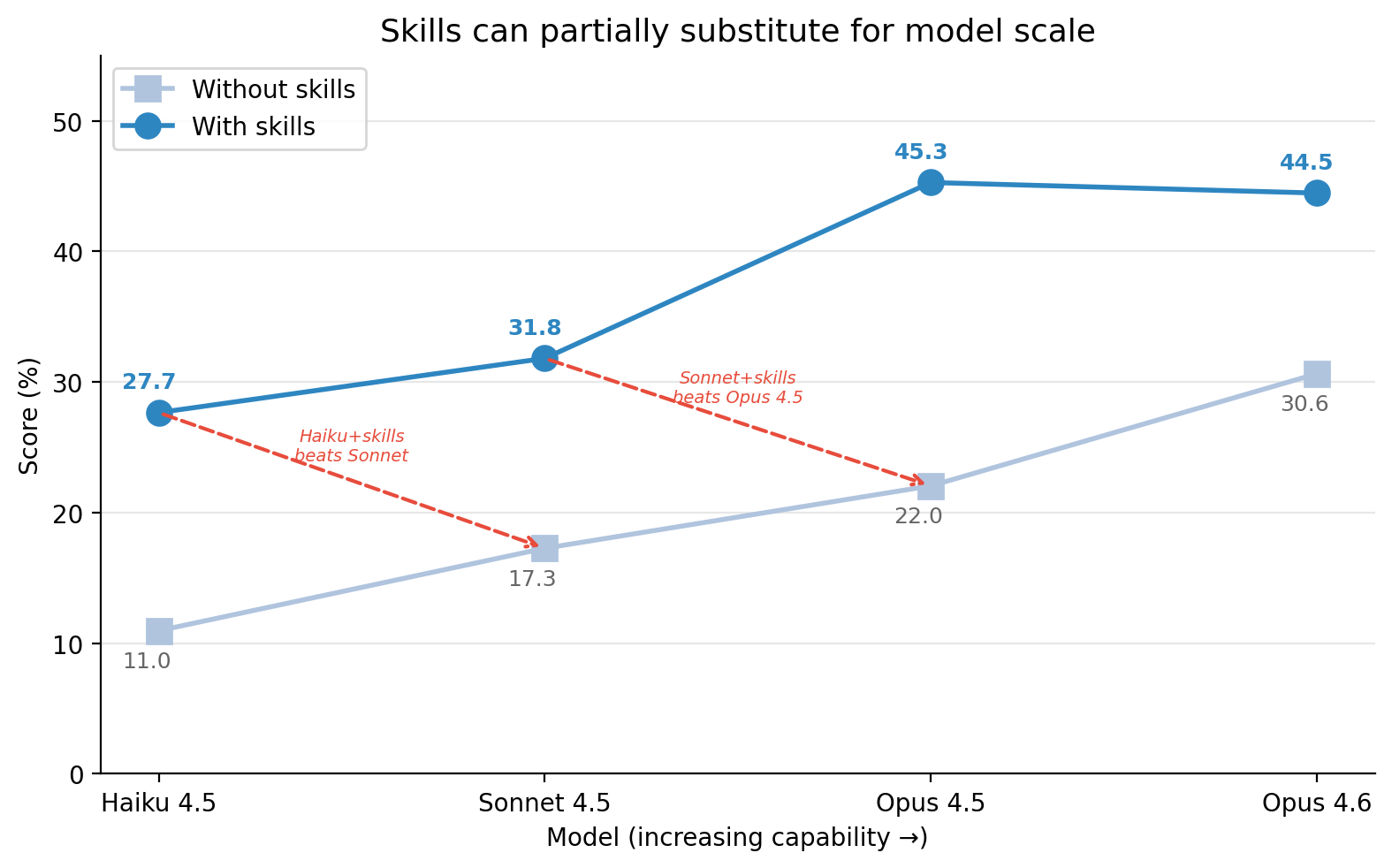
Model scale vs skills effectiveness
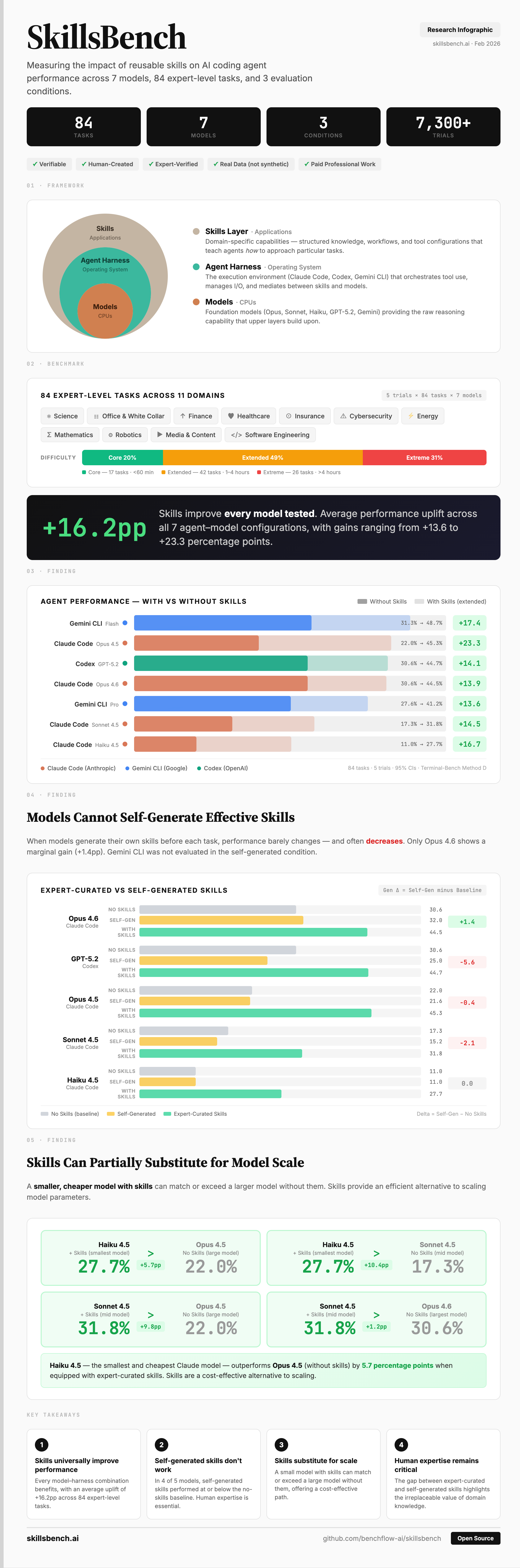
Comprehensive results across 84 tasks, 7 models, 3 conditions
Links