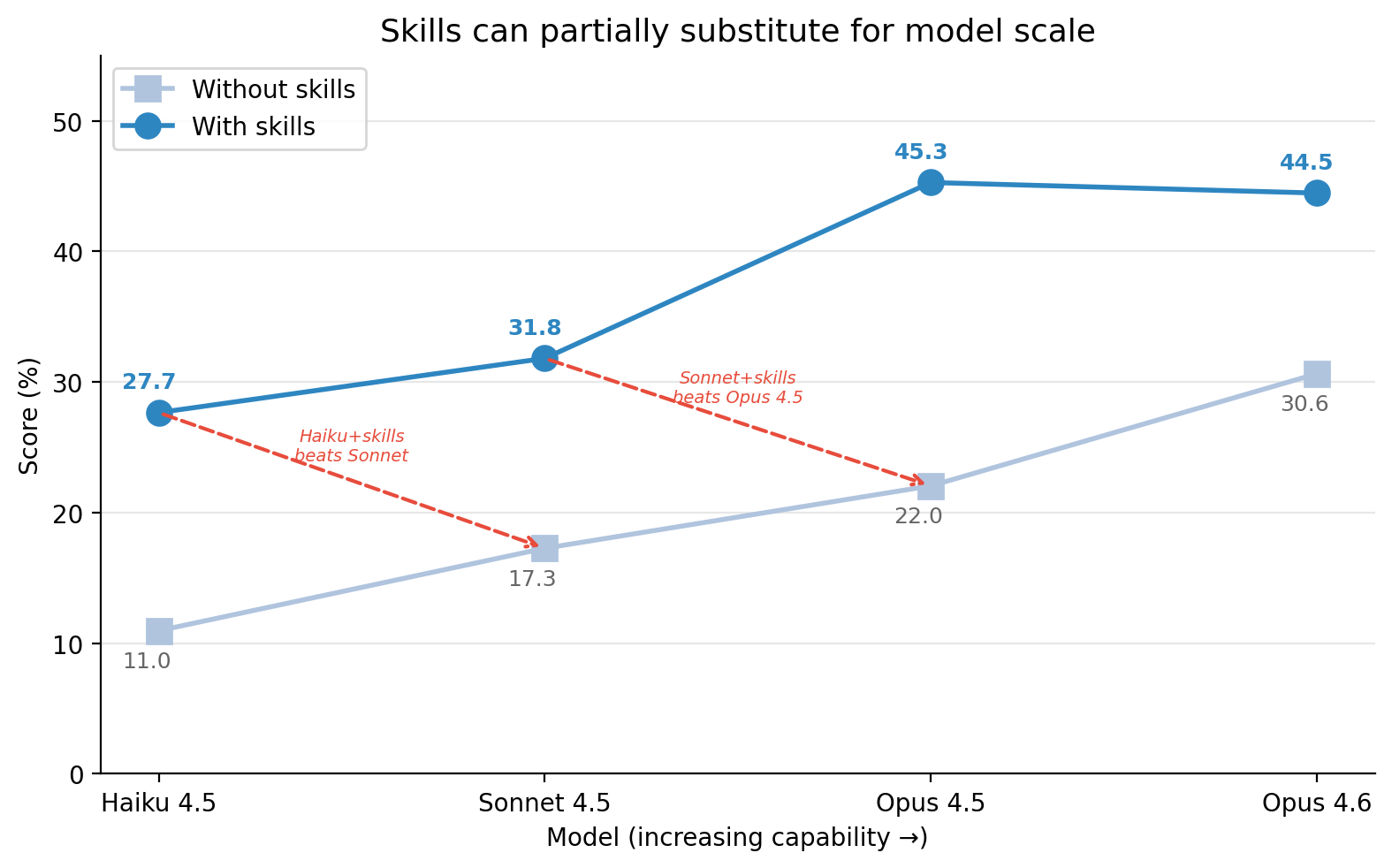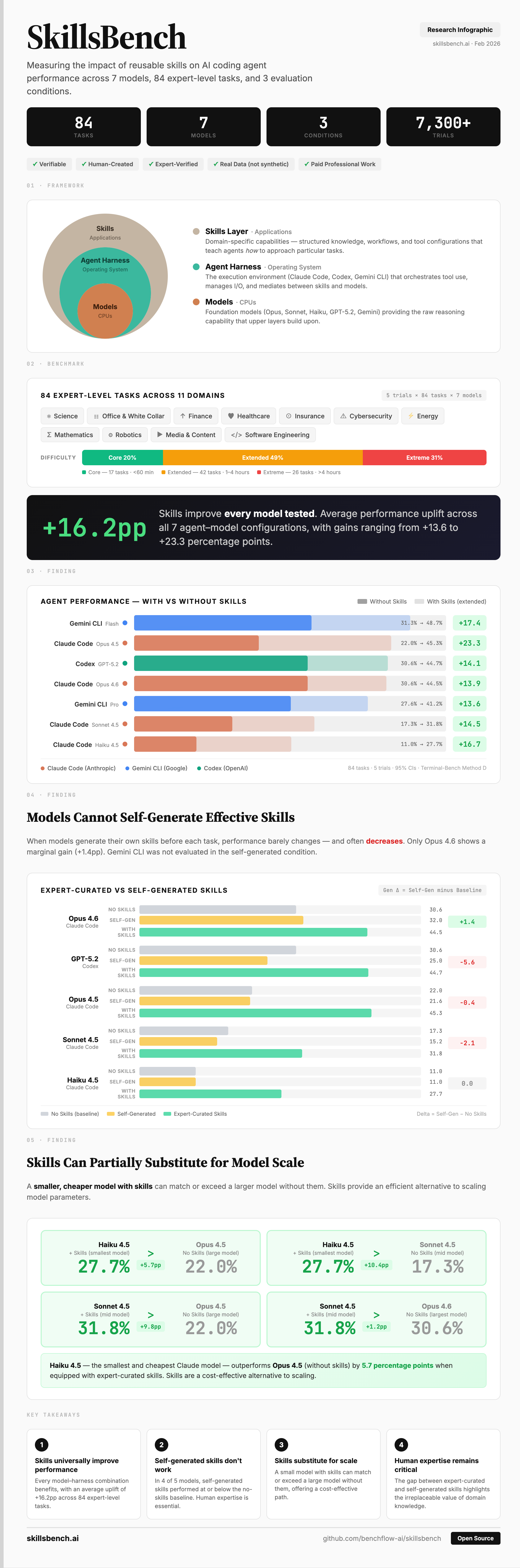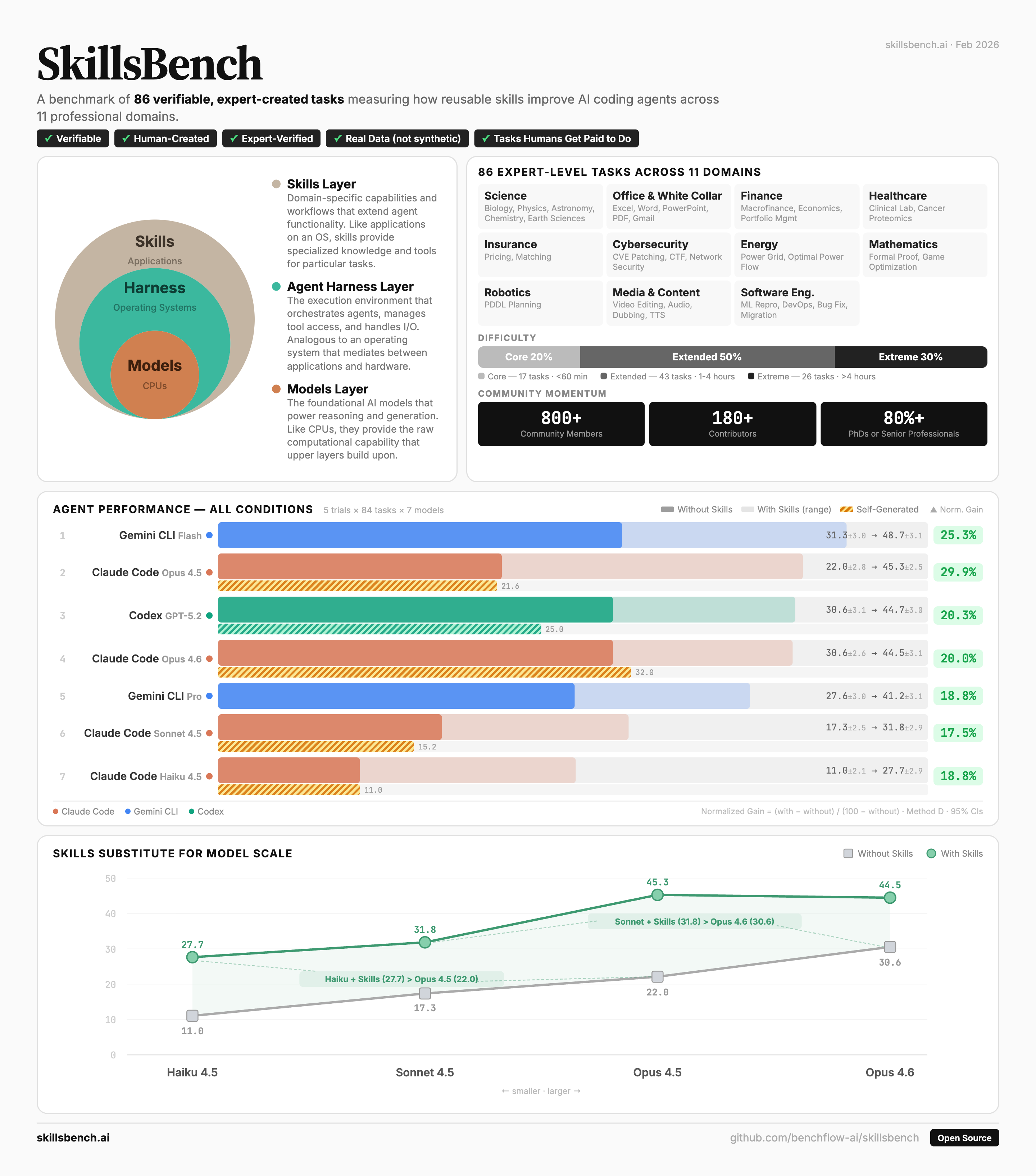
When you mount the right skill, do agents get more real work done? That's the question SkillsBench was built to answer. A skill is a reusable bundle — instructions, examples, scripts, references — that an agent loads on demand the way a junior would consult a checklist. Skills enable agent deployment across domains; the benchmark measures whether that pays off.
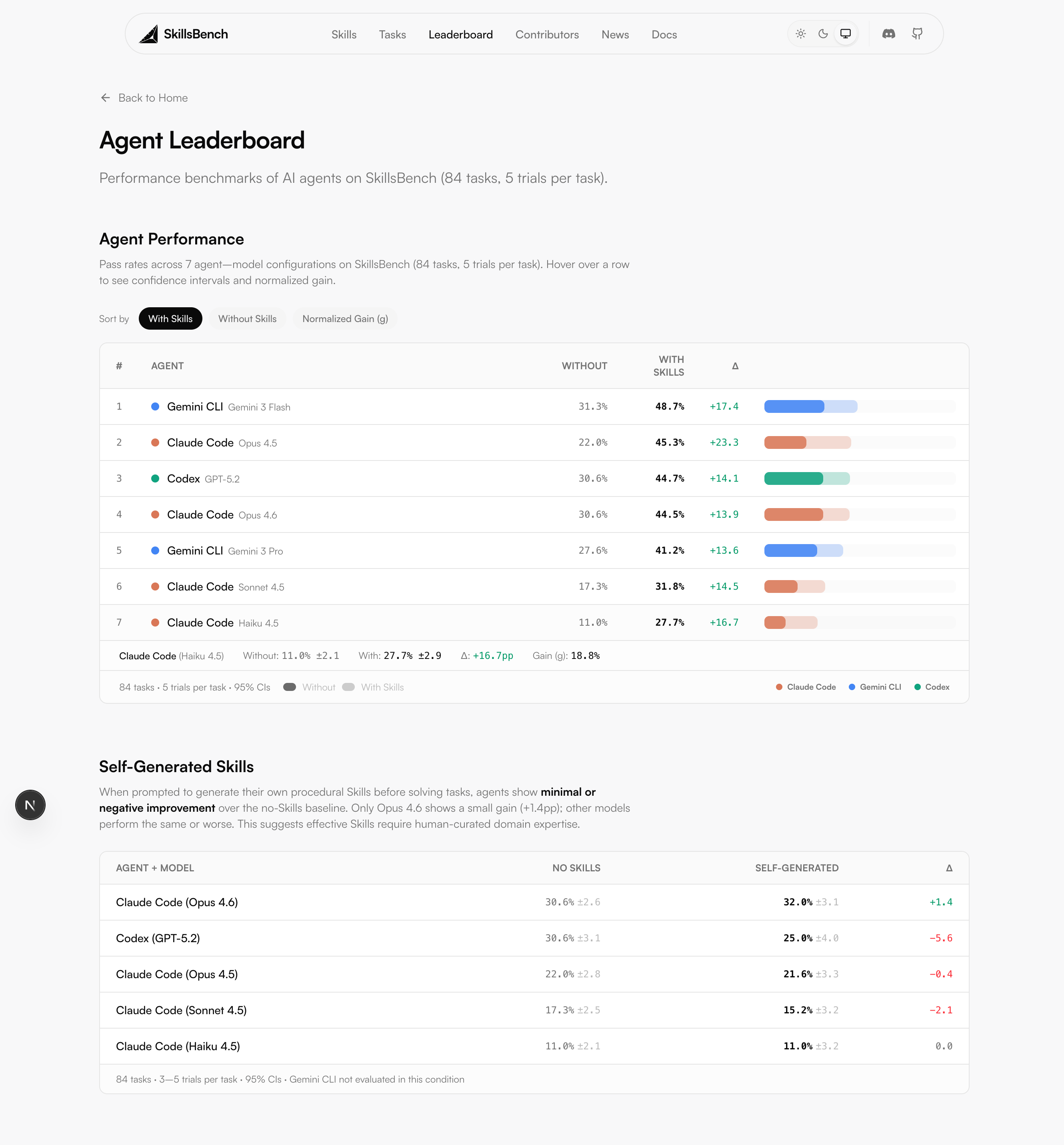
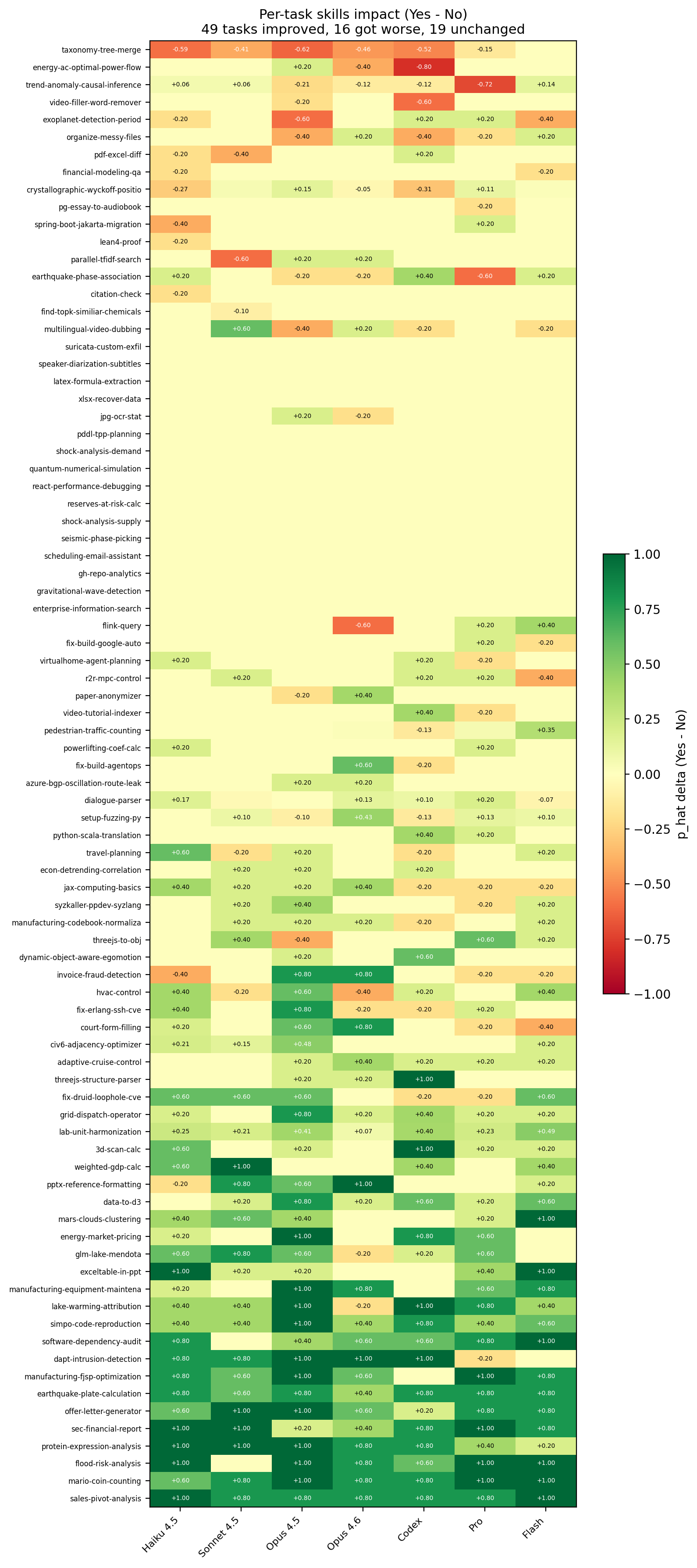
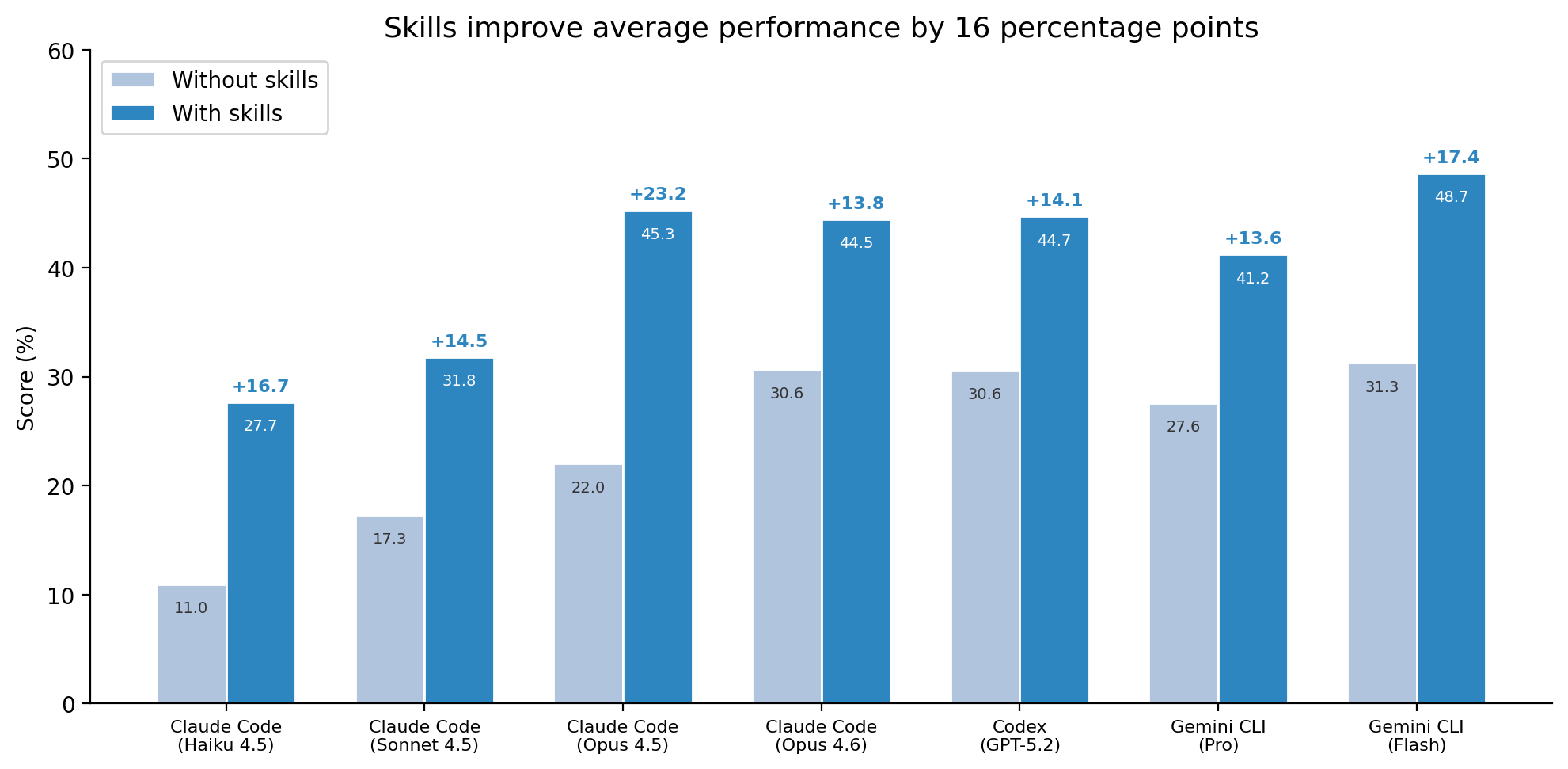
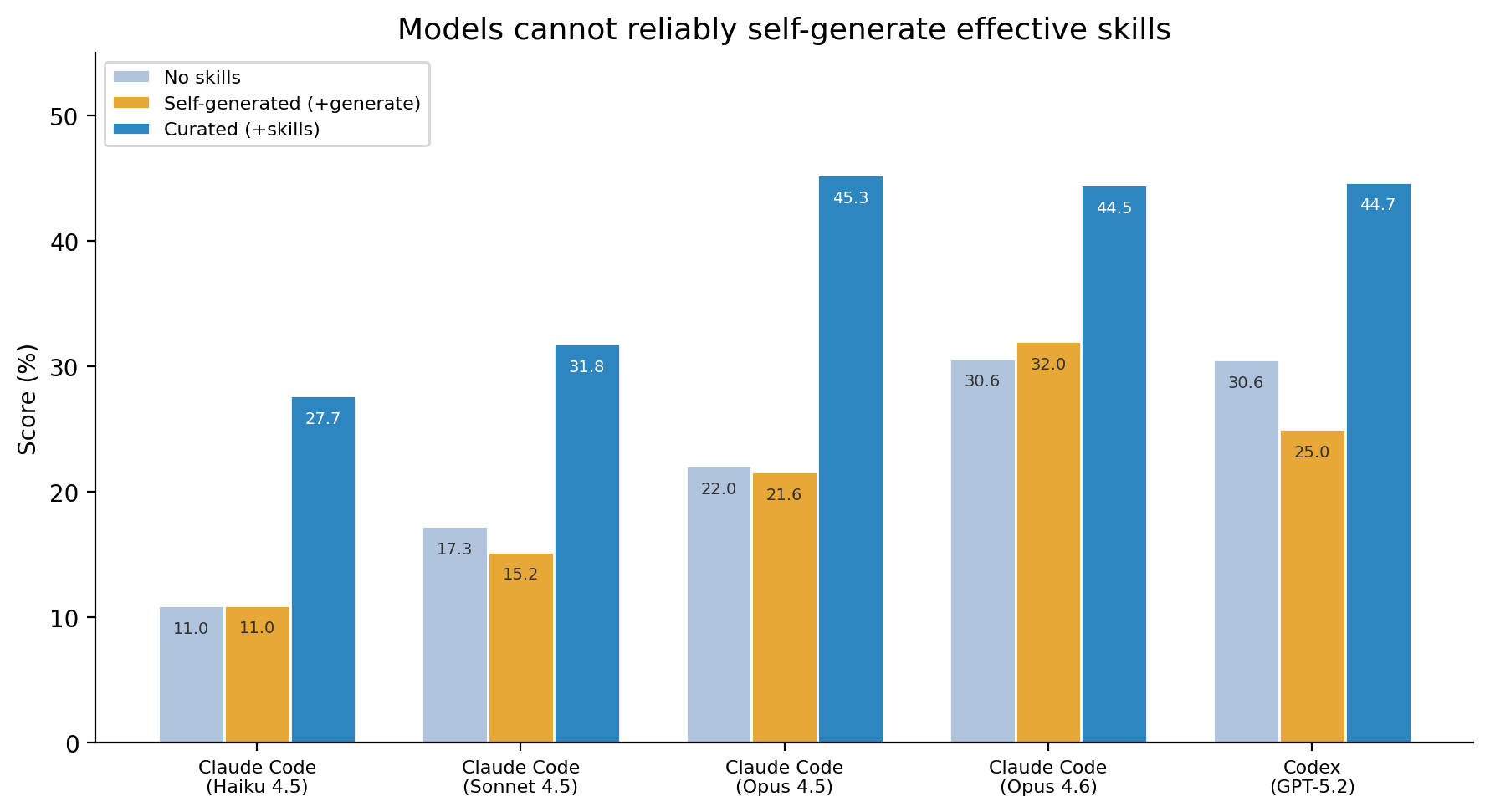
86 tasks span 11 professional domains: science, finance, healthcare, cybersecurity, energy, media, office work, software engineering, and more. Each task ships an oracle solution and an outcome-based verifier. 7,308 trajectories across the public sweep, 41 co-authors. The paper went up February 2026; the live leaderboard is at skillsbench.ai.
Traction in the first eight weeks: 23+ citations on Semantic Scholar, cited in the Qwen 3.6 Max model card, and used internally at Tencent, GLM, Minimax, Google DeepMind, Meta, and Microsoft. DeepMind quality-filtered SkillsBench down to a 60-task set for their internal eval; GLM and Qwen pushed for a no-external-deps build, so we shipped SkillsBench Lite alongside.
Two hackathons in March 2026 (Founders, Inc. on Mar 7 and AGI House on Mar 14) brought 600+ participants, with the strongest submissions reviewed and merged into the public benchmark. The inaugural Agent Skills workshop was accepted into ACM CAIS 2026 — one of five workshops accepted that year. Discord went 50 → 600 members across the same window.
Open source so labs can pressure-test their own skill ecosystems before shipping.