BenchFlow is the SDK and cloud runtime for agent eval. The first harness, environment, and benchmark unification framework — built late 2024, before DeepSeek R1, before the current agent-eval wave. Hosted 60+ benchmarks (SWE-Bench, WebArena, Terminal-Bench), generated $50K+ in revenue and 100K+ trajectories before the category had a name.
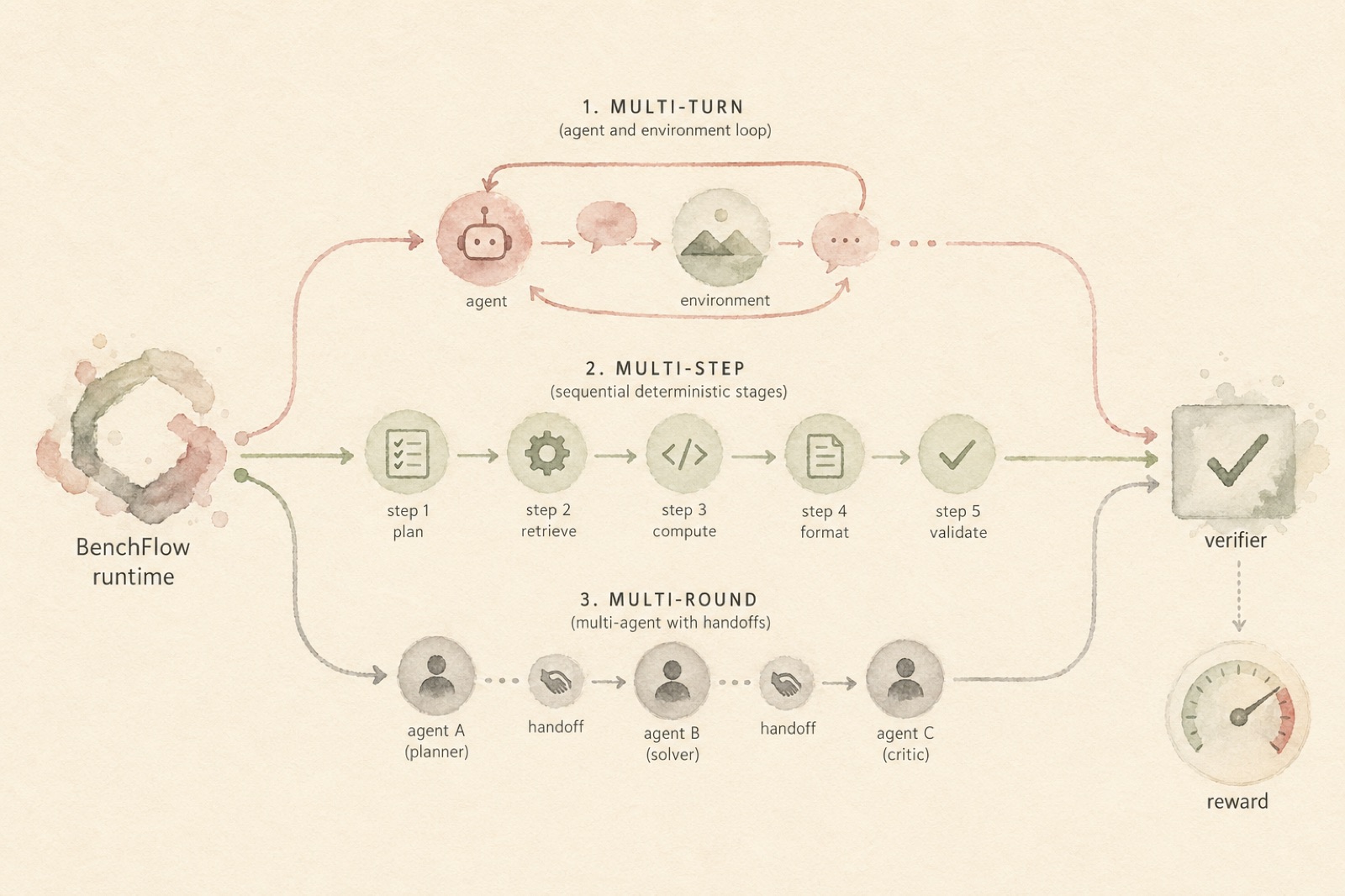
Models are the cars; people building with models are the drivers. We build the track. Any ACP agent — Claude Code, Codex, Gemini, OpenCode, OpenHands, OpenClaw, Pi, your own — runs through one Scene/Role/Turn primitive. Multi-turn (agent ↔ environment), multi-step (deterministic sub-procedures the environment enforces), multi-round (multi-agent setups with handoffs and adversarial probes), BYOS (bring your own skills) — all share the same lifecycle.
Hardened verifier blocks BenchJack-class reward hacking out of the box: the 0.0 → 1.0 exploits that flipped scores on prior versions are denied at the verifier layer; tasks opt back in per-feature when they need to. Dense reward signals follow the `ext-openrewardstandard` shape so the same trajectories drive SFT, RL, and reward-model training without re-instrumentation.
Powers SkillsBench and ClawsBench end-to-end. Runs locally (Docker) or in cloud sandboxes. Open source.
